What Exactly is a Vector Database?

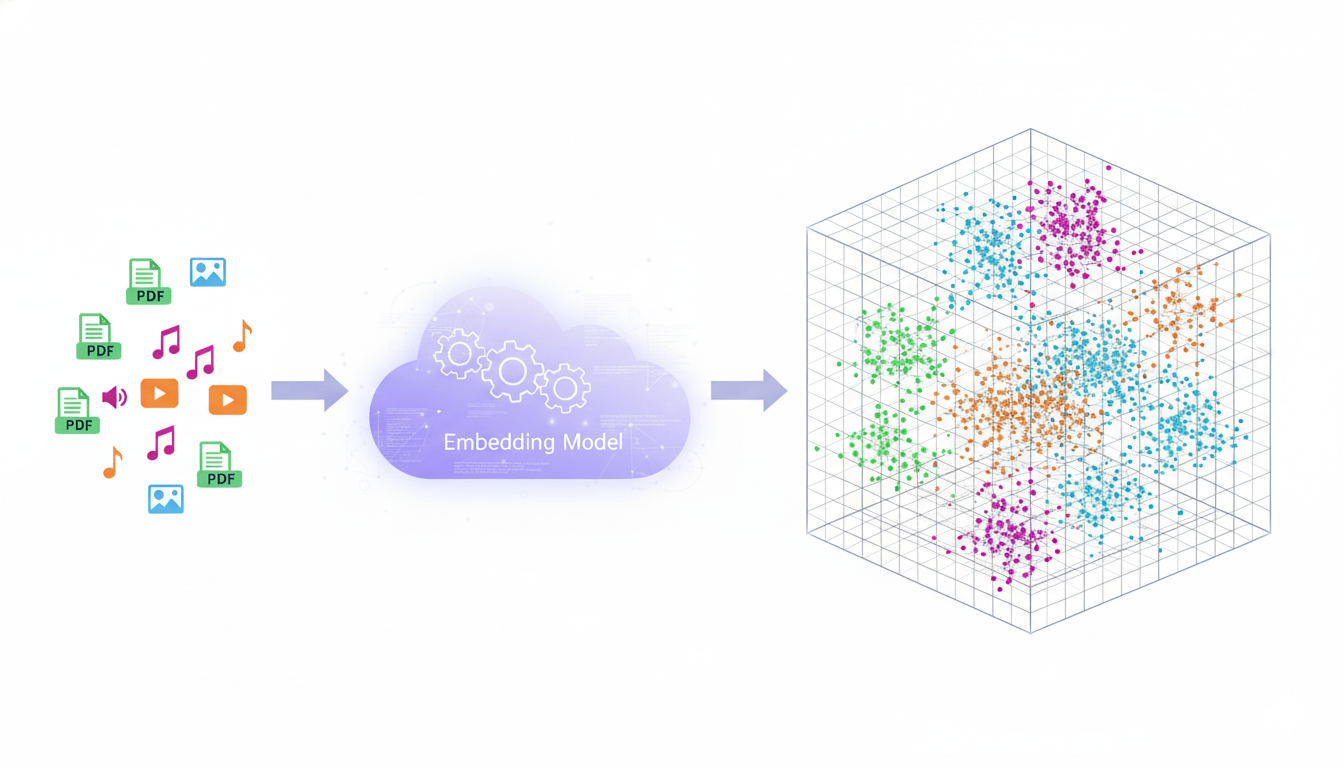
A Vector Database isn't just a simple storage unit for words; it's essentially a smart filing system that looks beyond the exact words you type to find the meaning behind them.
Here's how it works:
In a traditional database, if you search for "dog," it only finds the precise word "dog." With a vector database, your text is transformed into a complex mathematical signature called an embedding. Now, words like "dog," "puppy," and "German Shepherd" all reside in the same conceptual area.
When you search, it feels like the system genuinely understands your intent. The process usually involves asking for the "top K" results, which simply means "give me the most similar items."
So, if you ask for the "top five," the database returns the five closest matches, each with a similarity score (like 0.93, 0.87, 0.75). The challenge is that some of those five might be highly relevant, while others are just noise. Imagine searching for "best local coffee shop" and getting two amazing cafes, a car wash, a bookstore, and a random social media post. Not very efficient!
The Re-Ranker: Your Quality Control
That's where you need a re-ranker. The re-ranker doesn't blindly accept the initial "top K" items. It pulls in a larger number of potential candidates, then re-reads them using the full context of your question to determine which ones actually provide the best answer.
Think of it this way: the Vector DB is an enthusiastic assistant who hands you 20 possibly relevant documents. The re-ranker is the calm, experienced manager who reviews them and says, "That's helpful, but let's set aside these 15. Only these five truly make sense." This drastically improves the quality of the final result.
Going Deeper with Knowledge Graphs
Next, you have knowledge graphs. These structures don't just understand meaning; they understand relationships. They know not only that "Einstein is a physicist," but also his theories, collaborators, and timeline of discoveries. It transforms simple facts into a rich, interconnected web of information—context taken to the next level.
Keeping it Focused with Metadata Filters
And don't overlook metadata filters. These allow you to precisely refine your search before it even starts. Want only documents created in 2023? Or only customer support tickets labeled "refund"? Metadata lets you quickly narrow down the data, ensuring you don't accidentally pull up irrelevant information, like a recipe when you're looking for legal contracts.
The Modern AI Stack
The effective modern AI search system is built as a complete pipeline:
- Vector DB gathers a large collection of potentially relevant material.
- Re-ranker cleans this collection, filters out poor matches, and reorders the results based on actual relevance.
- Knowledge Graph adds depth by connecting everything with defined relationships.
- Metadata keeps all searches focused and efficient.
By putting these pieces together, your AI system moves beyond just guessing. It can find, filter, and truly reason with information.
Vector databases were a major innovation in 2021. However, if you rely only on that in 2025, you're missing out on the full power of modern AI systems. I'm starting a community where I'll break down the integration of AI and automation, step by step, using real workflows and practical examples.

MindPlix is an innovative online hub for AI technology service providers, serving as a platform where AI professionals and newcomers to the field can connect and collaborate. Our mission is to empower individuals and businesses by leveraging the power of AI to automate and optimize processes, expand capabilities, and reduce costs associated with specialized professionals.
© 2024 Mindplix. All rights reserved.