MLC LLM: How to Run Big Artificial Intelligence on Your Laptop

AI in Your Pocket: What Is MLC LLM and Why Is It Convenient?
Have you ever wondered why we almost always need the internet to talk to smart neural networks like GPT? The answer is simple: they are too heavy. Usually, the "brains" of these systems live on giant servers. But the MLC LLM project offers a bold alternative: running powerful AI directly on your device, whether it’s a laptop or even a smartphone.
I think this fundamentally changes the feeling of working with the technology. First, there is privacy. Your requests—whether personal messages or proprietary code—never fly off to a remote server. They are processed right "under the hood" of your machine. Second, speed. You aren't dependent on Wi-Fi quality or company server loads. Strangely enough, local execution often turns out to be faster than the cloud, especially for short tasks.
A Bit of Technical Magic: How the "Compiler" Optimizes Tensors for Your Chip
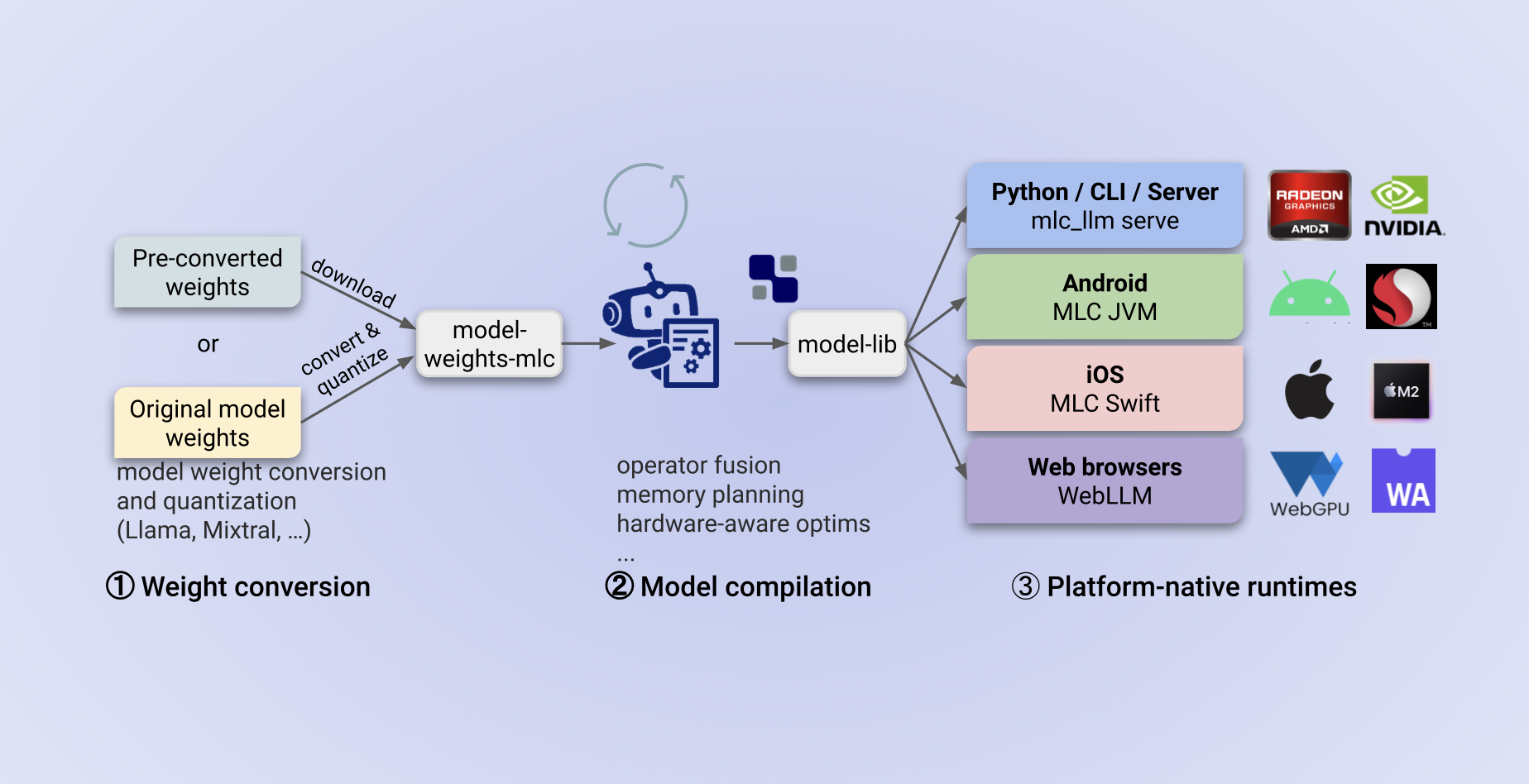
But how do you fit a giant into a small box? It must be admitted, there is real engineering magic happening here. Inside any neural network lie tensors. To simplify, a tensor is a huge multi-dimensional table of numbers where the model's knowledge is encoded. For your computer to work with them, these tables need to be "read" efficiently.
MLC LLM works as a universal compiler. Imagine that the neural network speaks a complex academic language, while your processor (CPU) or graphics card (GPU) understands only simple, chopped commands. MLC LLM takes the original model and translates it into a language understood specifically by your hardware, using Apache TVM technology. It doesn't just run the model. It optimizes it for your specific architecture—be it an Apple M3 chip, an NVIDIA card, or even the graphics in your browser (WebGPU).
I’ve seen tests where such optimization yielded performance gains of several times compared to standard execution. This allows you to "squeeze" the maximum out of home hardware.
Power Limits: Model Size Restrictions and Hardware Requirements
However, don't think that you can now run "anything and everything" on an old phone. There are strict physical limits. The main enemy of local AI is memory shortage.
To run a model, it must be fully loaded into RAM (or video memory). Original models weigh hundreds of gigabytes. To get around this, developers use quantization. This is a compression process where we intentionally lower the precision of the numbers in those tensors. For example, instead of storing a number with 10 decimal places, we store only 2.
- The Result: The model "slims down" by 3-4 times.
- The Trade-off: It becomes slightly less smart, but it fits into the memory of a standard PC.
If you want to run the popular Llama-3-8B model, you will need a graphics card with at least 6–8 GB of video memory (VRAM). But for monsters at the 70B level, you will need professional equipment with 24 GB+ of memory or even two graphics cards. There are no miracles: you have to pay for intelligence with gigabytes.
Who Can Benefit from This Tool?
So what does this mean in dry residue? Who wins from this technology?
- For Developers: This is your safe sandbox. Usually, developing AI applications feels like a taxi ride: the meter is ticking for every cloud API token used. Made a mistake in the code? Did the script get stuck in a loop and send a thousand extra requests in a minute? Congratulations, you just accidentally "burned" the project budget. With MLC LLM, this fear disappears. You run the model on your own hardware, so any errors and experiments cost exactly zero dollars. I would say this completely unties your hands for creativity. You can test the wildest hypotheses without looking at your bank balance. Plus, forget about the internet. Your application will work completely autonomously—whether on a plane or in a basement without a connection.
- For Business: This is security. Law firms or clinics that are not allowed to upload client data to the public cloud can now use the power of LLMs locally. Data remains strictly within the company perimeter.
- For Researchers: This is accessibility. Students and scientists can experiment with neural network architectures on their laptops without spending thousands of dollars renting cloud clusters.
MLC LLM makes technology that was elite just yesterday accessible to anyone with a modern computer.

MindPlix is an innovative online hub for AI technology service providers, serving as a platform where AI professionals and newcomers to the field can connect and collaborate. Our mission is to empower individuals and businesses by leveraging the power of AI to automate and optimize processes, expand capabilities, and reduce costs associated with specialized professionals.
© 2024 Mindplix. All rights reserved.