The Colosseum of Code: Why the Chatbot Arena Is the Only AI Benchmark That Actually Matters

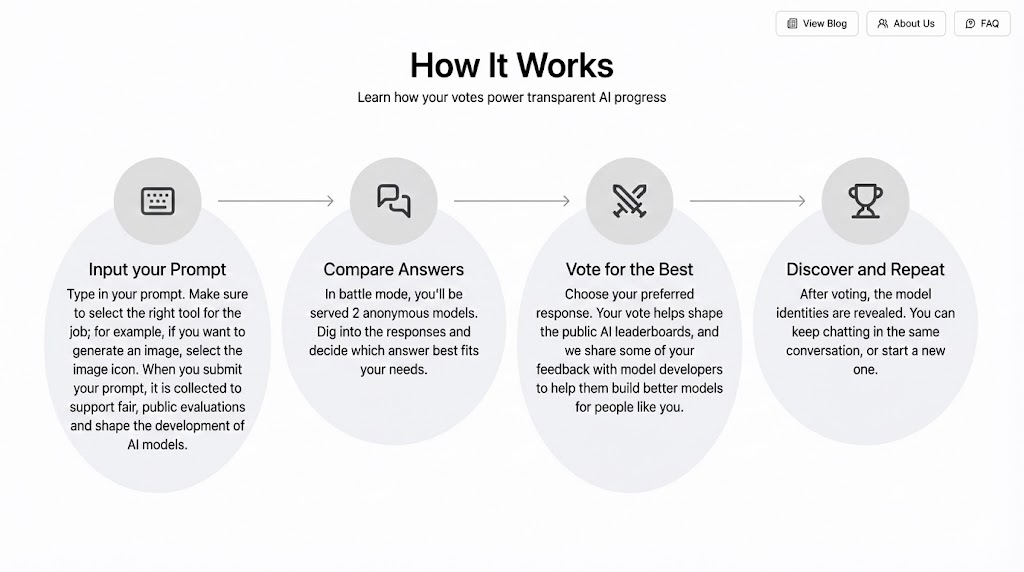
LMArena operates like a high-stakes blind taste test for AI. The workflow is deceptively simple: you input a prompt—selecting the right tool, whether for text or image generation—and enter "battle mode," where two anonymous models generate competing responses side-by-side.
You act as the judge. After digging into the answers, you vote for the one that best fits your needs. This isn't just feedback; your vote directly shapes the public leaderboards and guides developers on how to build better models. Only after you cast your ballot are the identities revealed, allowing you to discover the winner before starting the cycle agai
The "Vibes" Problem
If you listen to the press releases, every new artificial intelligence model is a genius. Google claims their latest Gemini outperforms human experts; OpenAI says GPT-4o is the pinnacle of reasoning; Anthropic insists Claude is the safest. They all release colorful charts showing their model scoring 99.8% on some obscure academic test like the MMLU (Massive Multitask Language Understanding).
But here’s the thing about benchmarks: they are becoming garbage.
We have reached a point of "contamination." Models have read the entire internet, which means they have likely read the very test questions we are using to grade them. It’s like a student memorizing the answer key before the final exam. They aren't smart; they’re just well-prepared.
This has created a crisis of trust. We don’t need another sterile lab test. We need a sanity check. We need to know how these things feel to use. Enter lmarena.ai (LMSYS Chatbot Arena), a website that looks like it was built in a dorm room but has quietly become the most important judge in Silicon Valley.
Inside the Thunderdome

The premise of the Arena is deceptively simple. It’s the Pepsi Challenge for superintelligence.
When you log in, you are presented with two anonymous chat windows: Model A and Model B. You type a prompt—maybe a Python script to scrape a website, or a request for a haiku about dishwashers. Both models generate an answer. You vote for the winner. Only after you vote are the identities revealed.
"It’s visceral. It’s messy. It’s human."
Behind this simple interface is serious academic rigor. Operated by the Large Model Systems Organization (LMSYS Org)—a research collective involving UC Berkeley, UC San Diego, and Carnegie Mellon University—the platform uses the Elo rating system. This is the same math used to rank Chess grandmasters. It doesn’t just count votes; it calculates the probability of one model beating another based on the difficulty of the opponent.
It strips away the marketing hype. In the Arena, a model can't hide behind a brand name. It either writes good code, or it loses.
The Leaderboard Obsession
For the tech giants, the Arena leaderboard has become an obsession.
I’ve watched the rankings shift like a stock market ticker. When a new model from Google or Anthropic drops, engineers flock to the Arena to see if it can dethrone the current king (usually a version of GPT-4). As Wired and The Vergefrequently note, shifting a few points on the LMSYS leaderboard is now headline news. It validates billions of dollars in R&D investment.
There is something democratizing about it. A small, open-source model from a French startup like Mistralcan suddenly appear in the top ten, embarrassing tech giants with trillion-dollar market caps. It forces honesty on an industry that thrives on smoke and mirrors.
The Flaw in the Machine
But if you stare at the Arena long enough, you start to see the cracks.
The system relies on human preference. And humans? We are easily manipulated. Researchers have documented a phenomenon called "verbosity bias." If a model writes a longer, more confident-sounding answer, we tend to vote for it, even if a shorter answer is more accurate.
Even worse is the "sycophancy" problem.
We are inadvertently training these models to be "yes men." If I ask a model to validate a wrong opinion, and Model A politely corrects me while Model B agrees with my delusion, I’m statistically more likely to vote for Model B. We like being told we are right. As noted by experts like Simon Willison and researchers analyzing the platform’s data, this creates a perverse incentive. Are we selecting for the smartest AI, or just the most charming one?
Conclusion: The Last Line of Defense
Despite these flaws, lmarena.ai remains our best defense against marketing spin. It captures the "vibes"—that ineffable quality of helpfulness that raw data can't measure.
Until we figure out how to measure true intelligence, we are stuck in the Arena, voting for the machine that makes us feel the smartest. It’s an imperfect mirror, but it’s the only one we have.

MindPlix is an innovative online hub for AI technology service providers, serving as a platform where AI professionals and newcomers to the field can connect and collaborate. Our mission is to empower individuals and businesses by leveraging the power of AI to automate and optimize processes, expand capabilities, and reduce costs associated with specialized professionals.
© 2024 Mindplix. All rights reserved.